이번에 회사에서 진행하고 있는 프로젝트에서 가상 쓰레드를 사용했는데 동료들과 이야기하다 보니 팀원분이나 다른 팀 동료분들이 알려달라고 하셔서 작은 세미나를 진행하게 됐다.
가상 쓰레드는 JDK 21에 정식기능으로 막 나왔을 때는 한창 핫했지만 JVM 내부의 synchronized 동작 방식으로 인한 pinning 이슈와 서드 파티 라이브러리들의 내부 구현 방식으로 인한 pinning들로 인해 짜게 식은 느낌이었지만, JDK 24 때 JEP 491로 인해 JVM 내부의 synchronized 동작 방식이 변경되며 해당 이슈가 해결돼서 그런지 LTS인 JDK 25에선 꽤 쓸만하게 올라온것 같다.
JDBC 드라이버들도 내부 구현도 JDK 21이 막 나왔을 때의 버전보다 virtual thread 친화적으로 개선되어 그런지 현재 상황에선 실무에서 쓸만해졌다고 생각이 든다.
✔ 선수 지식
1. 기본적인 쓰레드 이해
2. ForkJoinPool
- ForkJoinTask
- Runnable/Callable 비슷한 작업 단위 인터페이스
- compute() 메서드 하나를 구현
- 작은 작업으로 쪼개고(fork()), 다시 합치는(join()) 용도
- ForkJoinWorkerThread
- ForkJoinPool 안에서 실제로 돌아가는 워커 쓰레드(플랫폼 쓰레드)
- 각 워커는 자신만의 WorkQueue(Deque)을 하나씩 가짐
- WorkQueue
- 각 ForkJoinWorkerThread가 가지는 double-ended queue(deque)
- 다른 워커가 work-stealing 시 LIFO 방식으로, pop() 방식으로 가져감
- 본인의 WorkQueue에서 작업을 가져올 땐 poll() 방식으로 가져옴
3. JFR (Java Flight Recorder)
- JVM 내부에서 일어나는 모든 이벤트(쓰레드 상태, GC, I/O, Lock contention, pinning 등)를 실시간으로 로깅하는 JVM 내장 프로파일링 시스템
- 특징
- 오버헤드가 낮음 (평균 < 1% CPU)
- 운영환경에서 사용해도 부담이 거의 없음
- JVM 내부 레벨의 정보를 매우 정확하게 캡처함
- VT 관련 이벤트까지 수집 가능
- 오버헤드가 낮음 (평균 < 1% CPU)
- 사용법
- JVM 옵션으로 JFR 실행
- java -XX:StartFlightRecording=name=myrecording,filename=record.jfr \\ -jar myapp.jar
- 실행 후 record.jfr 파일을 JDK Misson Control로 열면 됨.
- JDK Mission Control(JMC) 사용
- jmc
- JFR 파일을 GUI에서 분석 가능
- 파란색/노란색 그래프 + 타임라인 + 이벤트 트리
- 실시간 모니터링 가능
- jcmd <pid> JFR.start
- jcmd <pid> JFR.dump filename=record.jfr
- 실행 중간에도 가능
- jcmd <pid> JFR.check
- Virtual Thread 관련 이벤트 확인 방법
- 위 이벤트들로 아래 사항 확인 가능
- 어디서 VT가 park 되었는지
- 어디서 VT가 pinned 되었는지
- 어떤 락을 기다렸는지
- 어떤 synchronized에서 block 되었는지
- 어떤 socket read/write가 발생했는지
- 위 이벤트들로 아래 사항 확인 가능
- jdk.VirtualThreadPinned jdk.VirtualThreadPark jdk.JavaMonitorEnter jdk.SocketRead jdk.SocketWrite
- JVM 옵션으로 JFR 실행
4. synchronized 내부 메커니즘
- synchronized는 모니터락(JVM ObjectMonitor) 사용
- ObjectMonitor = OS mutex 기반 모델
- → OS(커널)가 제공하는 뮤텍스(락)을 써서 구현함
- ObjectMonitor = OS mutex 기반 모델
- 내부 메커니즘
- synchronized 진입 시 monitorenter 바이트코드 실행
- CAS(Compare And Swap) 시도 → 가벼운 락(lightweight lock) 시도
- 실패 시 → heavy monitor lock 획득 (ObjectMonitor 구조)
- 락 획득 실패 시 OS 레벨에서 BLOCKED 상태로 전환되거나 CPU busy loop 획득 대기 가능
- monitor exit 시 monitorexit 바이트코드 실행
5. synchronized와 ReentrantLock의 차이
- synchronized
- JDK 23-
- 경쟁 발생 시 OS의 mutex 기반 → 커널 개입, 비용 큼
- JDK 24+
- block 상황에서 OS mutex 개입을 가능한 한 회피하도록 개선
- 구현은 JVM ObjectMonitor에서 관리
- Java의 instrinsic monitor
- 비선점(non-interruptible), timeout 없음
- JDK 23-
- ReentrantLock
- 완전히 Java 레벨에서 구현된 Lock
- CAS(Compare And Swap) 기반 user-space 락
- → 커널 개입 없음
- 락 상태는 객체 내부 변수로 관리
- 경쟁 시에도 Java 레벨에서 queue 관리
- OS 스케줄러에 맡기지 않고 JVM이 대신 관리
- LockSupport.park() 사용
- timeout, tryLock, interruptible 등 고급 기능 제공
- 완전히 Java 레벨에서 구현된 Lock
6. FFM (Foreign Function & Memory API)
- JDK 22에서 표준(Standard) 채택된 API
- Java에서 네이티브 코드(C/C++ 라이브러리)와 네이티브 메모리(io_uring, C structs, DirectBuffer 등)를 JNI 없이 직접 다루도록 만든 언어 수준의 공식 인터페이스
- FFM 제공 핵심 기능
- Foreign Function (함수 호출)
- C 함수, 시스템 라이브러리, DB 라이브러리 등 JNI 없이 직접 호출 가능
- 예시 코드
- Linker linker = Linker.nativeLinker(); MethodHandle mh = linker.downcallHandle(funcAddress, descriptor); mh.invokeExact(args...);
- 특징
- JNI처럼 핸들러/Env 필요 없음
- Java 타입 ↔ C 타입 안전 변환 자동 제공
- 성능이 JNI보다 좋고, 유지보수성이 높음
- C 함수, 시스템 라이브러리, DB 라이브러리 등 JNI 없이 직접 호출 가능
- Foreign Memory (네이티브 메모리 접근)
- Heap 밖의 메모리 (C malloc 영역, struct, off-heap buffer 등)을 Java에서 안전하게 읽고 쓰는 기능 제공
- 예시 코드
- Arena arena = Arena.ofConfined();
MemorySegment seg = arena.allocate(64);
seg.set(ValueLayout.JAVA_INT, 0, 123);
- 특징
- Bounds-checking, lifetime 관리로 안전성 향상
- ByteBuffer 보다 훨씬 강력하고 타입 안전
- Heap 밖의 메모리 (C malloc 영역, struct, off-heap buffer 등)을 Java에서 안전하게 읽고 쓰는 기능 제공
- Foreign Linker & Symbol Lookup
- C 라이브러리 심볼을 로드하고 함수 주소를 가져오는 기능
- 예시 코드
- SymbolLookup stdlib = SymbolLookup.libraryLookup("c", ...); MemorySegment printfAddr = stdlib.find("printf").get();
- C 라이브러리 심볼을 로드하고 함수 주소를 가져오는 기능
- Foreign Function (함수 호출)
✔ 가상 쓰레드란?
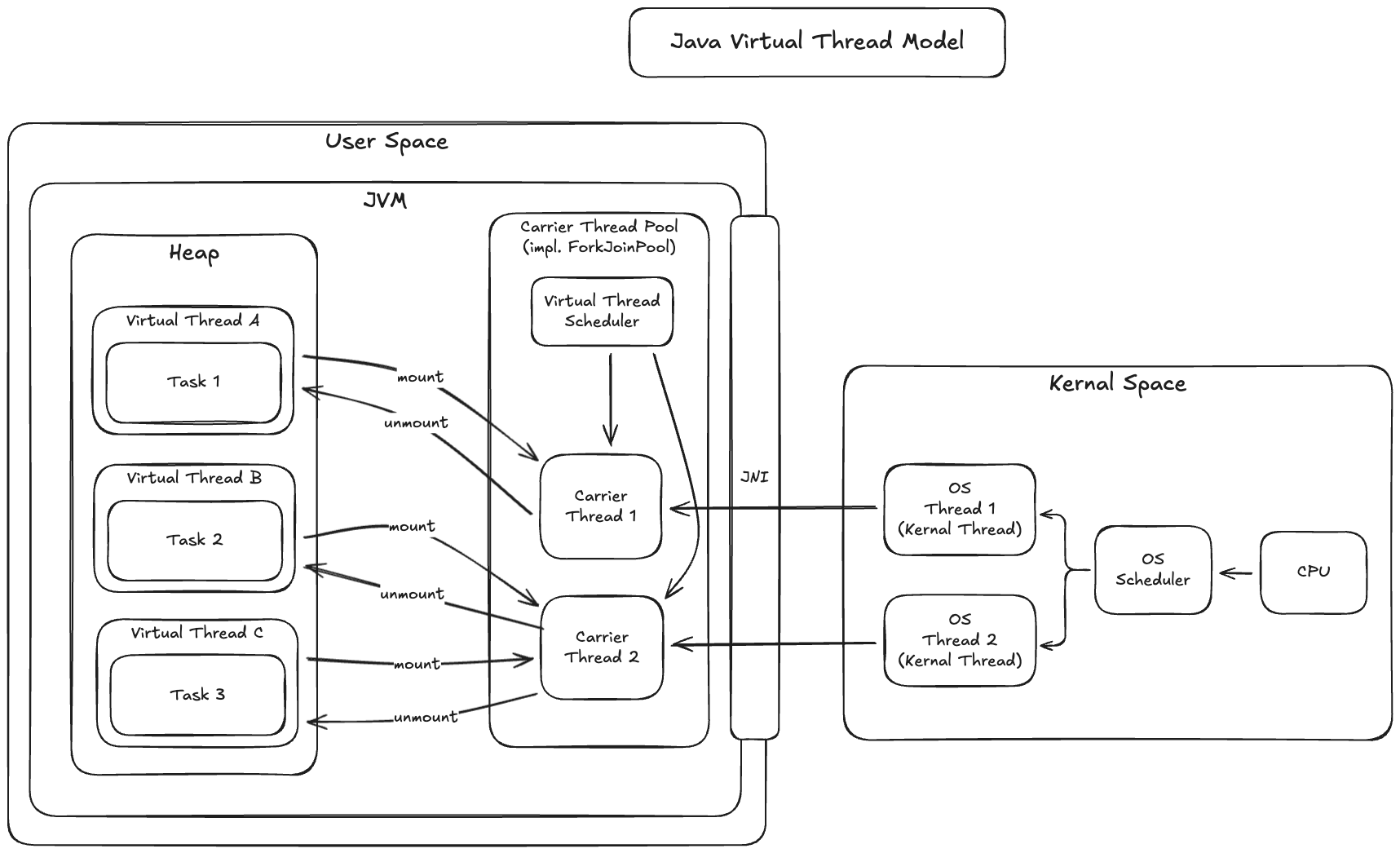
- Project Loom에서 만든 OS 쓰레드에 1:1 매핑되는 플랫폼 쓰레드와 달리 JVM 내부에서 사용자 공간 스케줄링되는 경량 스레드
- java.lang.Thread의 한 구현체
- 실제 실행은 플랫폼 쓰레드 위에서 동작하나, 블로킹 I/O를 만나면 해당 플랫폼 쓰레드에서 떼어내고(unmount) 다른 작업에 재사용하여, 플랫폼 쓰레드가 블로킹 상태로 기다리며 리소스를 낭비하는걸 방지함.
- JVM이 관리하는 user-level thread
Project Loom의 설계 이념 및 목표
Project Loom은 ‘가볍고, 수백/수천/수만 동시 작업을 감당할 수 있는 user-mode 스레드’ 를 제공하여, 기존 Java의 스레드 기반 동기 코드 모델을 거의 그대로 유지하면서, 높은 처리량(high throughput), 낮은 리소스 비용, 쉬운 유지보수 & 디버깅
- 경량 스레드 + 고동시성 (lightweight + high concurrency)
- lightweight threads that dramatically reduce the effort of writing, maintaining, and observing high-throughput concurrent applications
- 코드 구조를 “간단한 동기(blocking) 스타일 → 비동기/콜백/리액티브 복잡성”으로 억지 변환하지 않고도, “수백/수천/수만 동시 요청 + I/O 대기 + 높은 처리량(high throughput)”을 감당할 수 있도록 만든다
- 기존 Thread-per-Request 모델 복구 + 호환성 유지
- 유지보수성, 디버깅, 프로파일링의 단순화
- 기존 비동기/리액티브 방식의 단점인 “콜백 지옥 / 제어 흐름 복잡 / stack trace 흐트러짐 / 디버깅 어려움”을 피하면서, “blocking + lightweight + 관찰 가능(conventional tooling)”을 실현한다
- 효율적인 리소스 활용 (OS 스레드, 메모리, 컨텍스트 스위칭 비용 절감)
- 언어 생태계 전체에 대한 통합(consolidation of concurrency models)
- Java 에서 concurrency model fragmentation을 줄이고, “blocking + lightweight + scalable”이라는 새 표준을 제시하는 것이 목표
- 목표
- OS 스레드 1:1 모델 한계 극복
- Thread-per-request 모델 복원
- 비동기/Reactive 대체 가능
- I/O 블로킹에서도 OS 스레드 점유하지 않기
- ‘전통적 동기 코드 스타일 + 확장성’ 양립시키기
✔ 가상 쓰레드의 장점
Virtual Thread 모델의 핵심은 Thread를 OS에게 맡기는 대신, JVM이 직접 스케줄링 한다는 것. 즉, Virtual Thread는 커널 쓰레드 갯수가 아니라, JVM의 스케줄링 자원에 의해 scaling 되며, 기존 blocking I/O 코드를 그대로 사용하면서 비동기 스타일 성능을 얻는 것.
- 가상 쓰레드 모델로 인해 블로킹 I/O 시 발생하는 쓰레드 점유 문제 개선
- 기존 Java의 플랫폼 쓰레드는 커널 쓰레드와 1:1 매핑으로, 블로킹 I/O 작업 발생 시 해당 쓰레드 상태가 변경되며, 이로 인해 OS 레벨에서 컨텍스트 스위칭 발생함.
- 하지만 가상쓰레드는 I/O 블로킹 발생 시 PARK 상태로 전환되며, 캐리어 쓰레드(플랫폼 쓰레드)를 점유하지 않고 다른 unmount 되어 다른 가상쓰레드를 해당 캐리어 쓰레드에서 작업할 수 있도록 함.
- 유저 스페이스에서 커널에 대한 블로킹 I/O를 비동기로 처리한다고 이해해도 괜찮음.
- 쓰레드 생성, 컨텍스트 스위칭 비용 감소
- 플랫폼 쓰레드와 가상 쓰레드 비교
항목 플랫폼 쓰레드 (OS Thread) 가상 쓰레드 (Virtual Thread) 생성 비용 매우 비쌈 (수십~수백 μs) 매우 저렴 (수 μs 이하) 메모리 스택 크기 ~1MB 이상 ~KB 단위 (OS 스택 없음) OS 자원 점유 OS 레벨 자원 사용 필요 JVM heap 객체만 사용 컨텍스트 스위칭 비용 높음 (커널 모드 전환 포함) 매우 낮음 (유저레벨 스케줄링) 블로킹 시 자원 점유 OS 쓰레드 지속 점유 언마운트되고 캐리어로부터 분리됨 동시 실행 가능한 수 수천 개 제한 수백만 개 가능 ThreadLocal 사용 가능 가능(단, 패턴 주의 필요) synchronized pinning 발생 가능 발생(주의 필요) IO 처리 방식 OS 차단 IO JDK 재구현 비차단 IO Scheduler OS scheduler JVM Virtual Thread scheduler 적합한 작업 CPU-bound IO-bound - 기존 동기/블로킹 스타일 코드를 유지한 채 동시성 향상
- 기존에 톰캣의 Worker Thread 갯수가 동시 처리 가능한 요청 수였다면, 가상쓰레드는 워커 쓰레드 수는 플랫폼 쓰레드 몇개에 불과하나, 실제론 그 위에서 수천~수만 개의 가상 쓰레드가 요청을 처리함. → 리액티브 모델로 재작성하지 않고도 외부 시스템과 HTTP I/O가 많은 서비스에서 동시성 확장 여지가 생김
- Thread per request 모델의 부활 + 튜닝 단순화
- 기존 플랫폼 쓰레드는 생성, 컨텍스트 스위치 비용으로 thread per request가 실질적으론 불가능
- → Netty 등이 적은 수의 플랫폼 쓰레드를 사용해 이벤트 루프로 처리 방식을 푸는 것과 같이 다른 모델을 적용해야함.
- 가상 쓰레드는 생성 비용과 메모리 사용량이 매우 적고 컨텍스트 스위칭 비용이 매우 저렴하여, 요청별로 쓰레드가 생성돼도 문제가 없음.
- 기존 플랫폼 쓰레드는 생성, 컨텍스트 스위치 비용으로 thread per request가 실질적으론 불가능
- 코드 복잡도 감소
- 비즈니스 코드는 기존과 동일한 순차/블로킹 코드 (try-catch, 트랜잭션, for-loop 등) 유지
- 콜백 지옥, 리액티브 모델, CompletableFuture 체이닝 같은 패턴을 강제하지 않기 때문에 읽기 쉬운 코드로 유지 가능
- 기존 블로킹 라이브러리와 좋은 궁합
- JDK 21에선 기존 Socket, ServerSocket, DatagramSocket API를 리팩토링하여 가상 쓰레드와 호환되도록 함.
- JDK 21 이전 기존 Java socket I/O 모델
- VT → Java Socket → JNI / native I/O → OS blocking syscall
- JDK 21+
- Socket API → Loom-aware I/O Layer → non-blocking I/O 기반
- → VT가 I/O 대기 시 unmount → Carrier Thread는 즉시 풀림
- Socket API → Loom-aware I/O Layer → non-blocking I/O 기반
- 아래 것들을 대부분 수정 없이 사용 가능하도록 함.
- JDBC (최신 드라이버)
- RestTemplate / RestClient / Apache HttpClient 등의 블로킹 HTTP 클라이언트
- 파일 I/O
- JDK 21 이전 기존 Java socket I/O 모델
- JDK 21에선 기존 Socket, ServerSocket, DatagramSocket API를 리팩토링하여 가상 쓰레드와 호환되도록 함.
- Spring 통합의 이점
- Spring / Spring Boot 차원에서 아래를 해줌
- TaskExecutor/TaskScheduler에 “virtualThreads” 지원 옵션 추가
- Boot에서 Tomcat/Jetty executor를 자동으로 가상 쓰레드 기반으로 교체
- 가상 쓰레드를 사용할 때는 SimpleAsyncTaskExecutor / SimpleAsyncTaskScheduler를 기본값으로 잡도록 자동 구성
- Spring / Spring Boot 차원에서 아래를 해줌
✔ 가상쓰레드의 단점
- CPU-bound 작업엔 맞지 않다.
- 짧게 실행되는 I/O 바운드 위주의 웹서비스에는 잘 맞으나, 긴 CPU-bound 작업 시 VT를 사용할 경우 다른 VT들을 starving 상태로 만들 수 있음.
- → 따라서 CPU-bound 코드는 VT에서 하지 않고, platform 쓰레드를 이용해 처리해야 한다.
✔ Java의 가상 쓰레드 지원 버전 및 버전별 변경점
JDK 19, 20
- preview로 제공
- Virtual Thread Scheduler가 별도의 특화된 스케줄러가 아닌 ForkJoinPool을 그대로 가져다 사용
JDK 21 (LTS)
- 정식 기능으로 포함 (JEP 444)
- Virtual Thread Scheduler → ForkJoinPool (FIFO mode)
- 일반 ForkJoinPool.commonPool과는 다름.
- Virtual Thread Scheduler
- work-stealing ForkJoinPool that operates in FIFO mode
- 일반 FJP의 LIFO 중심보다 큐(FIFO) 쪽에 맞게 튜닝
- commonPool
- 기본적으로 CPU-bound 작업을 위한 일반 JFP(LIFO 위주)
- Virtual Thread Scheduler
- 일반 ForkJoinPool.commonPool과는 다름.
- synchronized, 네이티브 호출로 인한 쓰레드 pinning 이슈 존재
- Socket 가상쓰레드 지원
- 네트워크 I/O (Socket, ServerSocket, DatagramSocket, HttpURLConnection 기반) API는 Virtual Thread 지원을 위해 재설계됨.
- 블로킹 I/O 호출 시 native syscall에서 직접 blocking 하지 않고, Java 사이드의 park/unpark 기반으로 변환되어, Carrier Thread pinning 없이 작동하도록 변경됨.
- 즉, 가상 쓰레드가 언마운트(unmount) 될 수 있게 JVM 레벨에서 개선됨.
JDK 22~23
- Virtual Thread 관련 API 보완
- 동시성 + I/O
JDK 24
- JEP 491
- synchronized가 더 이상 VT를 pinning하지 않게 한다는 목표의 개선점
- synchronized로 인한 pinning 이슈 해결
- synchronized 내부 블로킹에도 unmount 가능하도록 변경됨. → pinning 발생 케이스 대부분 제거됨.
- 따라서 현재 pinning은 주로 JNI/native/FFM blocking 구간에서 발생함
- VirtualThreadSchedulerMXBean 추가 등 스케줄러 튜닝, 모니터링 강화
- jdk.VirtualThreadPinned JFR 이벤트는,
- synchronized가 pinning을 안 하게 된 이후에도,
- native 호출 → 그 native가 다시 Java로 콜백 → 그 안에서 block 같은 케이스 등
- 여전히 발생 가능한 pinning을 추적하는 데 계속 쓰일 예정.
- jdk.VirtualThreadPinned JFR 이벤트는,
- Runnable 임계값 기반 Carrier 추가 정책 등으로 실체감되는 스케일링/안정성 개선
JDK 25 (LTS)
- JEP 491을 포함한 가상 쓰레드 관련 개선이 그대로 들어온 상태
- StructuredTaskScope 정식 API로 정리
| 항목 | JDK 21 | JDK 24 |
| CarrierThreadPool | 초기 도입 | 최적화됨 |
| I/O unmount | 안정적 | 더 빠름 |
| pinning 발생율 | 낮음(약간 남음) | 매우 낮음 |
| continuation 저장 | 효율적 | 압축 개선 |
| epoll poller | 일반적 | io_uring 사용 증가 |
✔ 가상 쓰레드 모델 구성요소

Virtual Thread
- java.lang.Thread ← java.lang.BaseVirtualThread ← java.lang.VirtualThread
- Java의 Thread를 상속한 객체
- 객체기 때문에 Heap에 생성되고 GC 대상이됨.
- 내부적으로 continuation이란 JVM 독자적 구조로 컨텍스트를 저장했다가, 다시 이어서 실행(resume) 가능한 구조로 구현됨.
- 생성자 코드 (JDK25)
// VirtualThread 생성자 (JDK 25 Eclipse Temurin)
VirtualThread(Executor scheduler, String name, int characteristics, Runnable task) {
super(name, characteristics, /*bound*/ false);
Objects.requireNonNull(task);
// choose scheduler if not specified
if (scheduler == null) {
Thread parent = Thread.currentThread();
if (parent instanceof VirtualThread vparent) {
scheduler = vparent.scheduler;
} else {
scheduler = DEFAULT_SCHEDULER;
}
}
this.scheduler = scheduler;
this.cont = new VThreadContinuation(this, task);
this.runContinuation = this::runContinuation;
}Continuation
- Virtual Thread의 중단 가능 실행 흐름을 캡슐화하는 객체
- 특정 코드 블록 (continuation body)에 대한 register, stack frame, local vars, resume 위치 등 실행 컨텍스트를 캡슐화
- yield 시점에 컨텍스트를 저장하고, 나중에 다시 run 해서 이어서 실행
- VirtualThread는 내부적으로 하나의 Continuation을 가진 Thread 객체처럼 구현되어 있음.
- Continuation cont = VirtualThread.cont
- 실제론 Continuation 위에 VirtualThread라는 Thread API 래퍼가 얹힌 구조
- 구조와 컨텍스트 저장, 복원 방식
- Stack 저장, 복원 방식
- Continuation은 JVM이 관리하는 Continuation 전용 스택(도메인)을 가지고 있고, 해당 스택에 쌓인 프레임들을 Heap 상의 구조로 복원 가능하게 관리함
- yield / park 시점에 Continuation이 관리하는 프레임들을 안전한 지점(재진입 가능한 지점)에서 재개 가능한 형태로 보존하는 것에 가까움.
- 플랫폼 쓰레드의 OS 쓰레드의 네이티브 스택 전체를 통째로 메모리 복사하는 방식이 아님.
- Continuation은 JVM이 관리하는 Continuation 전용 스택(도메인)을 가지고 있고, 해당 스택에 쌓인 프레임들을 Heap 상의 구조로 복원 가능하게 관리함
- 구조
- Continuation은 Heap Object도 아니고, Stack 도 아니고 JVM 내부의 관리되는 구조체다.
- Continuation 컨텍스트는 JVM 내부 메모리 구조(Managed stack 구조)에 저장되며, 일반 Heap 객체가 아니므로 GC 대상이 되긴 하나, GC가 이를 이동(compaction)하거나 정리하지 않는다.
- 일반 GC 대상처럼, reference를 가지는 객체고, GC reachable이면 생존, unreachable이면 GC로 제거되는 것은 동일.
- → GC root에서 참조되지 않는 Continuation은 GC 대상으로 지정된다.
- 하지만 일반 Heap Object 처럼 GC compaction 대상이 아니고, continuation stack frame은 이동되지 않는다 (non-movable)
- GC Mark & Sweep 에는 포함되나, GC가 continuation 내부 데이터를 이동시키진 않음.
- Continuation은 Heap Object도 아니고, Stack 도 아니고 JVM 내부의 관리되는 구조체다.
- Stack 저장, 복원 방식
- Kernel Thread(OS Thread)와 Virtual Thread의 컨텍스트 스위치 차이점
항목 OS thread Virtual thread 실행 레벨 kernel user space (JVM) context switching 비용 높음 매우 낮음 stack 고정 크기 (MB 단위) continuation 기반, 매우 작음 스케줄링 커널 스케줄러 JVM 스케줄러 sleep, I/O 대기 OS blocking VT unmount (park) 생성 비용 매우 높음 매우 저렴 수량 가능 수천~수만 수백만 단위 가능
runContinuation
- 해당 VirtualThread에 연결된 Continuation을 실제 캐리어 쓰레드에서 한 번 실행(또는 재개)시키는 진입점.
- 메커니즘
- 캐리어 쓰레드가 VT를 실행하기로 결정 시 run() 또는 내부 헬퍼에서 runContinuation() 비슷한 메서드 호출
- runContinuation() 내부에서
- VT.state → RUNNING
- 현재 캐리어 쓰레드를 mount (VT → carrier 바인딩)
- Continuation.run() 또는 유사 래퍼 호출
- Continuation.run() 동작
- 첫 실행 시 body 처음부터 실행
- 재개면 마지막 yield / park 지점 이후부터 재개
- 실행 중
- VT가 정상 반환 → VT.state → TERMINATED
- VT 내부에서 yield/park/Blocking I/O → Continuation이 중단되고 runContinuation()이 중단된 상태로 반환됨
- 이 때 VT는 PARKED 또는 적절한 상태로 전환
- scheduler가 이 VT를 글로벌 큐에서 내려놓고, I/O 완료 시 다시 글로벌 큐에 올림
Scheduler
- VirtualThread 멤버 변수로 가지고 있는 scheduler를 통해 Carrier Thread Pool에서 임의의 carrier를 빌리고 반납하는 구조에서 사용되는 스케줄러
- → 즉 VirtualThread.scheduler는 VT의 스케줄링을 담당하지 않고, VT의 스케줄링을 담당하는 CarrierThreadPool에 위임하는 executor 역할의 인터페이스
- 자체 스케줄링하지 않는다.
State
- 가상 쓰레드의 상태
private static final int NEW = 0;
private static final int STARTED = 1;
private static final int RUNNING = 2; // runnable-mounted
// untimed and timed parking
private static final int PARKING = 3;
private static final int PARKED = 4; // unmounted
private static final int PINNED = 5; // mounted
private static final int TIMED_PARKING = 6;
private static final int TIMED_PARKED = 7; // unmounted
private static final int TIMED_PINNED = 8; // mounted
private static final int UNPARKED = 9; // unmounted but runnable
// Thread.yield
private static final int YIELDING = 10;
private static final int YIELDED = 11; // unmounted but runnable
// monitor enter
private static final int BLOCKING = 12;
private static final int BLOCKED = 13; // unmounted
private static final int UNBLOCKED = 14; // unmounted but runnable
// monitor wait/timed-wait
private static final int WAITING = 15;
private static final int WAIT = 16; // waiting in Object.wait
private static final int TIMED_WAITING = 17;
private static final int TIMED_WAIT = 18; // waiting in timed-Object.wait
private static final int TERMINATED = 99; // final state
// can be suspended from scheduling when unmounted
private static final int SUSPENDED = 1 << 8;
Virtual Thread Scheduler (Carrier Thread Pool)
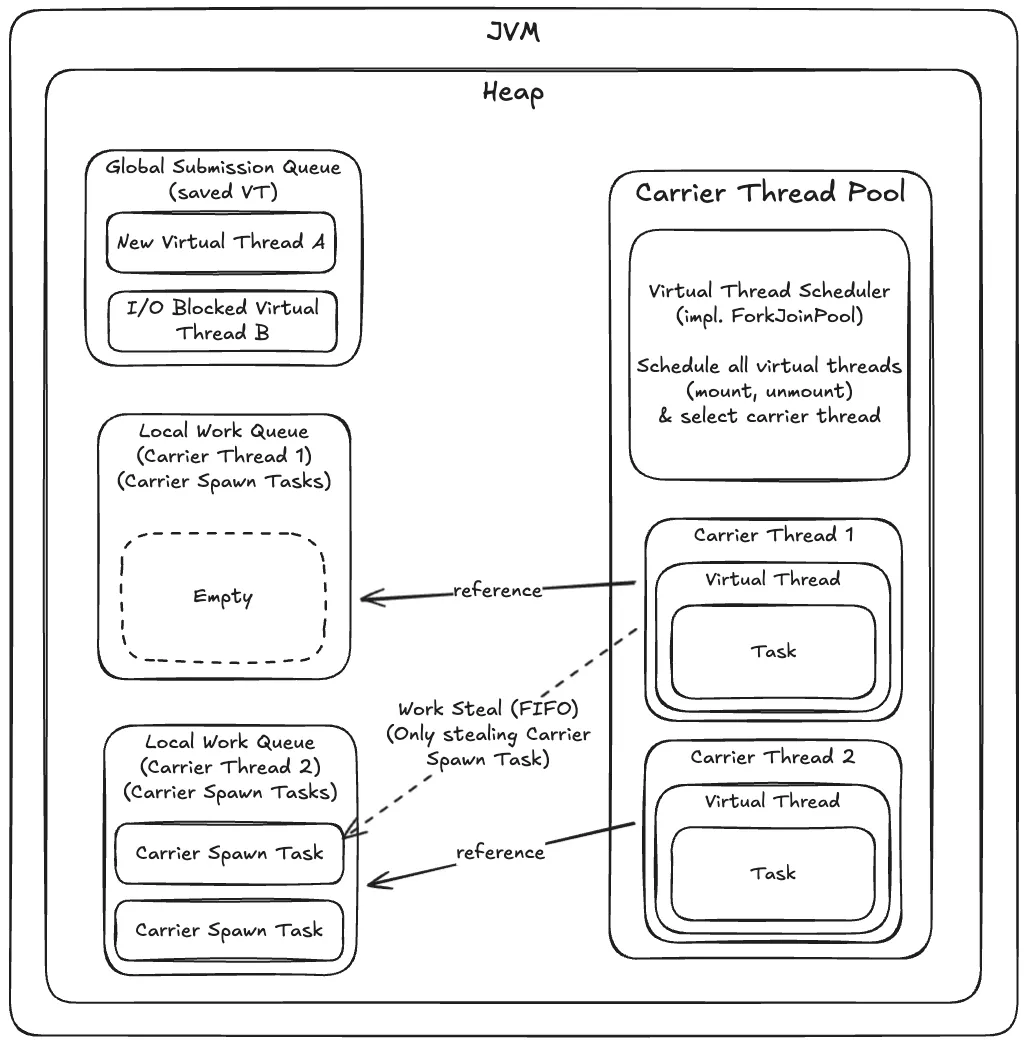
VirtualThread.scheduler가 아닌 Virtual Thread들에 대한 실제 스케줄링을 수행하고 mount 시키는 JVM 내부 Carrier Thread Pool
- VT에 대한 스케줄링은 CarrierThreadPool 내부에 구현되어 있음
- 각 CarrierThread는 VT를 실행하는 executor worker의 역할
[VirtualThread]
scheduler.execute(this)
↓
[CarrierThreadPool]
→ CarrierThread 선택
→ VT 실행 (mount)
- 내부 구현 (Internal)
- 구현체는 기본 ForkJoinPool을 사용하되, 기존의 commonPool과 다르게 FIFO mode로 튜닝되어 있는 전용 ForkJoinPool 사용.
- CompletableFuture 등의 비동기와 공유되지 않고, VT 스케줄링 전용으로 동작함.
- 구현체가 ForkJoinPool 이므로, Work Stealing 기능 존재
- 기존 ForkJoinPool(commonPool)과의 차이점
- 용도가 다름 (가상 쓰레드 전용)
- commonPool에서 사용하는 쓰레드는 ForkJoinWorkerThread
- 가상 쓰레드 전용풀에서 CarrierThread는 ForkJoinWorkerThread를 상속받은 별도의 클래스 (CarrierThread.java)
- Work Stealing의 기준점이 다름
- 기존 commonPool의 경우 Work Stealing이 LIFO 중심(Deque.pop())이었다면, FIFO로 튜닝됨. (Deque.poll())
- Work Stealing은 오직 Carrier 가 생성한 Task만 steal한다. (local queue 대상)
- 용도가 다름 (가상 쓰레드 전용)
- Scheduler는 커스텀 스케줄러 사용 불가
- VT 생성자 쪽에선 Executor를 인수로 받는 부분이 있으나, 캡슐화되어 사용자 코드 상에서 커스텀 스케줄러를 대신 쓰도록 전달할 방법은 없음. (private package 접근제어자)
- 마찬가지로 VirtualThreadFactory에도 scheduler를 인수로 받는 부분은 있으나, 캡슐화되어 사용자 코드에서 커스텀 스케줄러를 주입하는 방법은 없음.
- 당연하게도 JDK를 커스텀할 경우 제외
- 다른 스케줄러를 사용하는 경우는 해당 가상 쓰레드를 생성한 쓰레드가 가상 쓰레드일 경우, 생성자를 호출한 가상 쓰레드의 스케줄러를 사용함.
- VirtualThread 생성자 및 팩토리 호출부 (JDK25)
-
더보기// ThreadBuilders.java 에서 VT 생성자 호출부
static Thread newVirtualThread(Executor scheduler,
String name,
int characteristics,
Runnable task) {
if (ContinuationSupport.isSupported()) {
return new VirtualThread(scheduler, name, characteristics, task);
} else {
if (scheduler != null)
throw new UnsupportedOperationException();
return new BoundVirtualThread(name, characteristics, task);
}
}
// ThreadBuilders.newVirtualThread() 호출부 ============
// Thread.java
public static Thread startVirtualThread(Runnable task) {
Objects.requireNonNull(task);
var thread = ThreadBuilders.newVirtualThread(null, null, 0, task);
thread.start();
return thread;
}
// ThreadBuilders.java
@Override
public Thread unstarted(Runnable task) {
Objects.requireNonNull(task);
var thread = newVirtualThread(scheduler, nextThreadName(), characteristics(), task);
UncaughtExceptionHandler uhe = uncaughtExceptionHandler();
if (uhe != null)
thread.uncaughtExceptionHandler(uhe);
return thread;
}
// ThreadBuilders.java
@Override
public Thread newThread(Runnable task) {
Objects.requireNonNull(task);
String name = nextThreadName();
Thread thread = newVirtualThread(scheduler, name, characteristics(), task);
UncaughtExceptionHandler uhe = uncaughtExceptionHandler();
if (uhe != null)
thread.uncaughtExceptionHandler(uhe);
return thread;
}
/* ========= VirtualThreadFactory에 scheduler ===== */
// ThreadBuilders.VirtualThreadFactory
private static class VirtualThreadFactory extends BaseThreadFactory {
private final Executor scheduler;
VirtualThreadFactory(Executor scheduler,
String name,
long start,
int characteristics,
UncaughtExceptionHandler uhe) {
super(name, start, characteristics, uhe);
this.scheduler = scheduler;
}
@Override
public Thread newThread(Runnable task) {
Objects.requireNonNull(task);
String name = nextThreadName();
Thread thread = newVirtualThread(scheduler, name, characteristics(), task);
UncaughtExceptionHandler uhe = uncaughtExceptionHandler();
if (uhe != null)
thread.uncaughtExceptionHandler(uhe);
return thread;
}
}
// ThreadBuilders.VirtualThreadBuilder
static final class VirtualThreadBuilder
extends BaseThreadBuilder implements OfVirtual {
...
@Override
public ThreadFactory factory() {
return new VirtualThreadFactory(scheduler, name(), counter(), characteristics(),
uncaughtExceptionHandler());
}
}
-
- 마찬가지로 VirtualThreadFactory에도 scheduler를 인수로 받는 부분은 있으나, 캡슐화되어 사용자 코드에서 커스텀 스케줄러를 주입하는 방법은 없음.
- VT 생성자 쪽에선 Executor를 인수로 받는 부분이 있으나, 캡슐화되어 사용자 코드 상에서 커스텀 스케줄러를 대신 쓰도록 전달할 방법은 없음. (private package 접근제어자)
- 구현체는 기본 ForkJoinPool을 사용하되, 기존의 commonPool과 다르게 FIFO mode로 튜닝되어 있는 전용 ForkJoinPool 사용.
- 공평성(fairness)을 보장하지 않음
- Virtual thread scheduling is cooperative and not strictly fair. (OpenJDK)
- 즉, VT는 선점(preemption)되지 않음 (CPU를 뺏지 않는다)
- 자발적으로 yield / await 시에만 양보한다.
- NUMA locality는 고려하지 않음
- NUMA (Non-Uniform Memory Access)
- 멀티 소켓 / 멀티 노드 시스템에서 CPU가 자기 로컬 메모리에 접근할 땐 빠르고, 다른 소켓/노드에 붙어있는 원격 메모리에 접근할 때는 느린 메모리 구조를 말함
- OS는 보통 어떤 쓰레드가 주로 접근하는 메모리 페이지는 해당 쓰레드가 속한 NUMA 노드 쪽에 두려고 하고, 스케줄러도 가능하면 그 메모리와 가까운 CPU에서 그 쓰레드를 돌리려고 한다.
- 즉, NUMA locality는 특정 쓰레드가 자기 메모리(페이지)와 같은 NUMA 노드에서 실행되고 있는 상태를 뜻함.
- → locality가 좋으면 메모리 access latency가 줄고 캐시 효율이 좋아짐.
- NUMA (Non-Uniform Memory Access)
- Carrier Thread 수를 정하는 방식
- The carrier threads are approximately equal to the number of available processors.
- CarrierThread 개수 == CPU 코어 수
- parallelism 기본값
- Runtime.getRuntime().availableProcessors()
- 최대 256
- 가변
- Global Queue로 작업관리
- 새로운 VT의 runnable(continuation)은 전부 Global Queue에 들어감.
- 큐와 스케줄러 데이터 구조는 JVM 힙 상의 평범한 객체이며, OS 레벨에선 보이지 않음.
- Work Stealing
- ForkJoinPool의 Work Stealing 개념
- carrier가 생성한 작업이 담겨있는 local work queue가 비면 다른 carrier의 local work queue에서 작업을 가져옴(stealing)
- 모니터링
- VirtualThreadSchedulerMXBean으로 모니터링 가능
- default Virtual Thread Scheduler 코드 (JDK 25)
private static ForkJoinPool createDefaultScheduler() {
ForkJoinWorkerThreadFactory factory = pool -> new CarrierThread(pool);
int parallelism, maxPoolSize, minRunnable;
String parallelismValue = System.getProperty("jdk.virtualThreadScheduler.parallelism");
String maxPoolSizeValue = System.getProperty("jdk.virtualThreadScheduler.maxPoolSize");
String minRunnableValue = System.getProperty("jdk.virtualThreadScheduler.minRunnable");
if (parallelismValue != null) {
parallelism = Integer.parseInt(parallelismValue);
} else {
parallelism = Runtime.getRuntime().availableProcessors();
}
if (maxPoolSizeValue != null) {
maxPoolSize = Integer.parseInt(maxPoolSizeValue);
parallelism = Integer.min(parallelism, maxPoolSize);
} else {
maxPoolSize = Integer.max(parallelism, 256);
}
if (minRunnableValue != null) {
minRunnable = Integer.parseInt(minRunnableValue);
} else {
minRunnable = Integer.max(parallelism / 2, 1);
}
Thread.UncaughtExceptionHandler handler = (t, e) -> { };
boolean asyncMode = true; // FIFO
return new ForkJoinPool(parallelism, factory, handler, asyncMode,
0, maxPoolSize, minRunnable, pool -> true, 30, SECONDS);
}
Carrier Thread
- 기존 Java의 플랫폼 쓰레드이나 jdk.internal.misc.CarrierThread 는 ForkJoinWorkerThread를 상속받는다.
- 기본 VT Scheduler의 구현체가 ForkJoinPool이라서.
- ThreadGroup이 CarrierThreadGroup으로 묶인다.
- 최대 캐리어 쓰레드 수 : 32787
- 자신만의 Local Queue를 가짐 (ForkJoinWorkerThread.workQueue)
- LocalQueue엔 오직 CarrierThread가 생성한 Task만 들어간다.
- VT는 task가 아니고 개발자가 API로 만든 독립적 실행 단위임.
- Work Stealing 주체
- local queue가 비면 다른 캐리어의 local work queue의 작업을 훔쳐옴
- → idle carrier 가 생기는 것을 최소화하는 전략
- Carrier Thread 생성자 (JDK 25)
public CarrierThread(ForkJoinPool pool) {
super(CARRIER_THREADGROUP, pool, true);
U.putReference(this, CONTEXTCLASSLOADER, ClassLoader.getSystemClassLoader());
U.putReference(this, INHERITABLETHREADLOCALS, null);
}
Global Submission Queue (Global Queue)
- 실행 대기 중인 VT 들의 공통 대기열
- 생성된 VT, unmount되었다가 RUNNABLE 상태가된 VT 모두 여기에 적재됨
- CarrierThread가 Global Queue에서 VT를 가져와 실행함.
- VT가 PARKED되면 큐에 다시 들어가지 않고, 다시 RUNNABLE 상태가 될 때 global queue에 들어감
- JVM Heap에 위치
Local Work Queue
- Carrier가 자기 자신이 추가로 만든 작업의 전용 큐 (Deque)
- Local Work Queue는 CarrierThread가 생성한 작업만 적재하는 전용 큐다.
- Carrier가 작업을 spawn 할 때 자기 Local Queue에 push
- VirtualThread는 절대 적재되지 않음
- VirtualThread는 개발자가 API로 만든 독립적 실행 단위이며, Carrier 내부에서 fork된 task가 아니다.
- Local Work Queue는 CarrierThread가 생성한 작업만 적재하는 전용 큐다.
- 각 Carrier Thread 별로 존재
- Local Queue가 사용되는 경우
- FJP 내부 fork() 호출, RecursiveTask 분할 등
- Java executor 모델
- StructuredTaskScope 내부 fork
- FJP-style 병렬 작업
- locality 보존 + 캐시 친화성 확보 목적
- JVM Heap 에 위치
- 일반적으로 work-stealing 대상이 됨.
✔ 가상쓰레드의 상태
VT state transitions (JDK 25)
NEW -> STARTED // Thread.start, schedule to run
STARTED -> TERMINATED // failed to start
STARTED -> RUNNING // first run
RUNNING -> TERMINATED // done
RUNNING -> PARKING // Thread parking with LockSupport.park
PARKING -> PARKED // cont.yield successful, parked indefinitely
PARKING -> PINNED // cont.yield failed, parked indefinitely on carrier
PARKED -> UNPARKED // unparked, may be scheduled to continue
PINNED -> RUNNING // unparked, continue execution on same carrier
UNPARKED -> RUNNING // continue execution after park
RUNNING -> TIMED_PARKING // Thread parking with LockSupport.parkNanos
TIMED_PARKING -> TIMED_PARKED // cont.yield successful, timed-parked
TIMED_PARKING -> TIMED_PINNED // cont.yield failed, timed-parked on carrier
TIMED_PARKED -> UNPARKED // unparked, may be scheduled to continue
TIMED_PINNED -> RUNNING // unparked, continue execution on same carrier
RUNNING -> BLOCKING // blocking on monitor enter
BLOCKING -> BLOCKED // blocked on monitor enter
BLOCKED -> UNBLOCKED // unblocked, may be scheduled to continue
UNBLOCKED -> RUNNING // continue execution after blocked on monitor enter
RUNNING -> WAITING // transitional state during wait on monitor
WAITING -> WAIT // waiting on monitor
WAIT -> BLOCKED // notified, waiting to be unblocked by monitor owner
WAIT -> UNBLOCKED // timed-out/interrupted
RUNNING -> TIMED_WAITING // transition state during timed-waiting on monitor
TIMED_WAITING -> TIMED_WAIT // timed-waiting on monitor
TIMED_WAIT -> BLOCKED // notified, waiting to be unblocked by monitor owner
TIMED_WAIT -> UNBLOCKED // timed-out/interrupted
RUNNING -> YIELDING // Thread.yield
YIELDING -> YIELDED // cont.yield successful, may be scheduled to continue
YIELDING -> RUNNING // cont.yield failed
YIELDED -> RUNNING // continue execution after Thread.yield
VT.state (JDK 25)
private static final int NEW = 0;
private static final int STARTED = 1;
private static final int RUNNING = 2; // runnable-mounted
// untimed and timed parking
private static final int PARKING = 3;
private static final int PARKED = 4; // unmounted
private static final int PINNED = 5; // mounted
private static final int TIMED_PARKING = 6;
private static final int TIMED_PARKED = 7; // unmounted
private static final int TIMED_PINNED = 8; // mounted
private static final int UNPARKED = 9; // unmounted but runnable
// Thread.yield
private static final int YIELDING = 10;
private static final int YIELDED = 11; // unmounted but runnable
// monitor enter
private static final int BLOCKING = 12;
private static final int BLOCKED = 13; // unmounted
private static final int UNBLOCKED = 14; // unmounted but runnable
// monitor wait/timed-wait
private static final int WAITING = 15;
private static final int WAIT = 16; // waiting in Object.wait
private static final int TIMED_WAITING = 17;
private static final int TIMED_WAIT = 18; // waiting in timed-Object.wait
private static final int TERMINATED = 99; // final state
// can be suspended from scheduling when unmounted
private static final int SUSPENDED = 1 << 8;
요약 및 상태별 의미
| State | 의미 | 언제 발생 |
| NEW | 생성되었지만 시작되지 않음 | Thread.start() 이전 |
| RUNNABLE | 실행 중 또는 실행 가능 | 캐리어 쓰레드에 mount 된 상태 |
| PARKED | 블로킹으로 인해 중단된 상태 | 블로킹 I/O, lock, sleep, wait 등 |
| PINNED | unmount 불가, 캐리어 쓰레드 점유 | synchronized, JNI 등 |
| TERMINATED | 실행 완료 후 종료 | 실행 종료 |
실행 흐름별 상태변화
- NEW → RUNNABLE
- start() 호출하면 Scheduler가 캐리어 스레드에 할당 (mount)
- RUNNABLE → PARKED
- 블로킹 I/O 호출
- JVM이 continuation으로 스냅샷 저장
- 캐리어 스레드 반환 (unmount)
- (핵심: OS 커널 thread를 점유하지 않음)
- PARKED → RUNNABLE
- Poller Thread가 readiness 신호 수신
- 다시 캐리어 스레드 빌려 mount
- RUNNABLE → PINNED
- synchronized 구문 진입
- 또는 JNI 호출
- 또는 native 메서드
- synchronized 구문 진입
- → 캐리어 스레드 점유
- TERMINATED
- 정상 종료 또는 예외 발생
가상 쓰레드 상태변화 Flowchart (요약)

✔ 가상 쓰레드 메커니즘
메커니즘 Flowchart
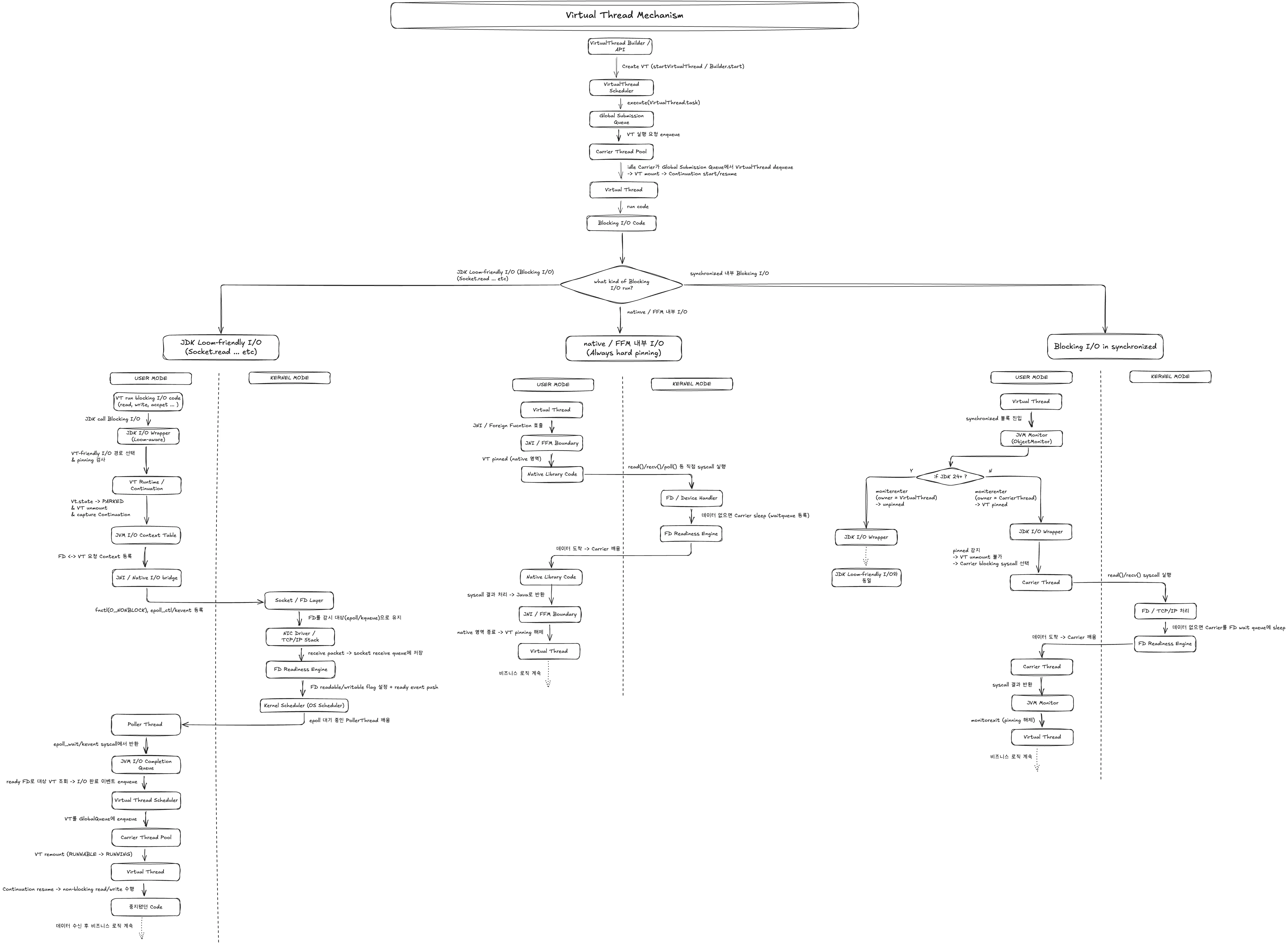
1. 정상적인 I/O 발생 시 (VT-friendly I/O)
RUNNABLE → PARKED → RUNNABLE
(mounted → unmounted → mounted)
- VT가 I/O 호출
- JDK Loom-friendly I/O Wrapper 검사
- Continuation 생성
- VT.state = PARKED 전환
- 캐리어 쓰레드에서 unmount됨
- I/O readiness 이벤트 발생
- VT 재스케줄
- 캐리어 쓰레드에 다시 mount → RUNNABLE
2. Pinning 발생 시 (synchronized + I/O)
RUNNABLE → PINNED → RUNNABLE
(mounted 유지)
- VT가 synchronized 영역 안에서 I/O 수행
- continuation suspend 불가
- VT가 CarrierThread 위에서 고정됨(pinned)
- CarrierThread가 그대로 커널 block
- I/O 완료
- VT 재실행
3. synchronized 내부 메커니즘
- JDK 21~23 (JEP 491 적용 이전)
- synchronized는 모니터락(JVM ObjectMonitor) 사용
- ObjectMonitor = OS mutex 기반 모델
- 내부 메커니즘
- synchronized 진입 시 monitorenter 바이트코드 실행
- CAS(Compare And Swap) 시도 → 가벼운 락(lightweight lock) 시도
- 실패 시 → heavy monitor lock 획득 (ObjectMonitor 구조)
- 락 획득 실패 시 OS 레벨에서 BLOCKED 상태로 전환되거나 CPU busy loop 획득 대기 가능
- monitor exit 시 monitorexit 바이트코드 실행
- synchronized는 모니터락(JVM ObjectMonitor) 사용
- JDK 24+ (JEP 491 적용)
- JVM 내부에서 ObjectMonitor 구현을 VT 친화적으로 변경함.
- ObjectMonitor = LockRecord + VT-aware wait 메커니즘
- 내부 메커니즘 변경점
- 기존
- VT 내부 synchronized → monitorenter → blocking in monitor → carrier pinned
- 변경 후 (JDK 24+)
- VT 내부 synchronized → monitorenter → block이 필요한 경우 → UNMOUNT 허용
- 즉, monitor wait 상태를 CarrierThread Blocking이 아닌 Continuation parking으로 변경.
- → kernel-level block을 user-level park로 변경
- JVM 내부에서 ObjectMonitor 구현을 VT 친화적으로 변경함.
VT의 mount/unmount 시점
- VT가 Blocking I/O에 진입 시
- 캐리어 쓰레드에서 내부 스케줄링 로직으로 언마운트
- unmount는 시스템 콜 이전에 발생함.
- JVM 내부에서 감지
✔ 사용법
- 필요 조건
- JDK 버전이 가상 쓰레드를 지원해야함. (정식지원 JDK 21 부터)
- 사용법
- JDK
- Thread.ofVirtual() 이나 Executors.newVirtualThreadPerTaskExecutor() , ThreadPoolTaskScheduler.setVirtualThreads(true) 등으로 각종 팩토리 메서드나 설정 등으로 간편하게 기존 코드에서 가상쓰레드로 전환할 수 있도록 제공해줌.
- SpringBoot
- Springboot 자동설정(application.yaml)의 spring.threads.virtual.enabled=true 로 설정
- 해당 설정 시 내장 톰캣의 worker thread가 가상쓰레드로 대체된다.
- → 즉, Tomcat의 TaskExecutor가 VirtualThreadTaskExecutor 로 대체됨
- 해당 설정 시 내장 톰캣의 worker thread가 가상쓰레드로 대체된다.
- 가상쓰레드 사용 시 worker thread pool size 조정 옵션은 무시된다.
- Springboot 자동설정(application.yaml)의 spring.threads.virtual.enabled=true 로 설정
- JDK
- 하면 좋은 것
- 네트워크 통신
- 외부 API 호출
- DB I/O
- NIO 소켓 I/O
- 순수 비즈니스 로직 (CPU 부담 낮음)
- 네트워크 통신
- 하면 안되는 것
- 강한 CPU-bound 연산
- 큰 배열 처리를 오랫동안 메모리 위에서 작업
- synchronized 내부에서 I/O 호출
✔ 가상 쓰레드 옵션
스케줄러 튜닝 옵션
- 스케줄러 튜닝 시스템 프로퍼티
- jdk.virtualThreadScheduler.parallelism
- 초기/기본 Carrier 스레드 수 (동시 실행 가능한 Carrier 수)
- default : 가용 CPU 코어 수 (Runtime.getRuntime().availableProcessors())
- jdk.virtualThreadScheduler.maxPoolSize
- I/O나 blocking 상황 등으로 Carrier가 부족할 때 최대 생성 가능한 Carrier 스레드 수 제한
- default : 256
- jdk.virtualThreadScheduler.minRunnable
- 풀 내 “유휴 Carrier 최소 유지 개수” 또는 “기본 활성 Carrier 개수” 관련 옵션 (환경마다 다름)
- 기본값은 max(parallelism / 2, 1)
- jdk.virtualThreadScheduler.parallelism
✔ Spring 에서의 가상 쓰레드
SpringBoot JDK 지원 버전
- 3.0 ~ 3.1 : java 17~Java20
- 3.2 : Java 21 (Virtual Thread 지원 시작)
- 3.3 : Java 17 ~ 23
- 3.4 : Java 17~24
- 3.5+ : Java 17~25
SpringBoot 가상 쓰레드 지원
- SpringBoot 3.2+ 에서 정식 지원
- spring.threads.virtual.enabled=true 설정 시 가상 쓰레드 통합 지원
- JDK 21+
- JDK 24+ (Recommended)
- SpringBoot 3.5.5+ 에서 JDK 25 공식 지원
SpringBoot의 가상쓰레드 사용 시 톰캣 구조
- spring.threads.virtual.enabled=true

Spring이 내부에서 바꾸는 것들 (Spring Boot 3.2+)
- 웹 요청 처리 (Tomcat Worker Thread)
- 내장 Tomcat의 요청 처리 Executor → VirtualThreadPerTaskExecutor 기반으로 변경
- → MVC 기준 각 HTTP 요청을 가상 쓰레드에서 처리함.
- 비동기 작업
- 비동기 작업의 AsyncTaskExecutor 의 구현체가 ThreadPoolTaskExecutor → SimpleAsyncTaskExecutor(Virtual Thread) 로 변경됨
- @Async / CompletableFuture 를 위한 기본 executor 등이 가상 쓰레드를 사용하게 됨.
- 스케줄링 (@Scheduled)
- TaskScheduler → SimpleAsyncTaskScheduler로 구성됨
- 풀 관련 설정 무시 (가상 쓰레드는 풀링 자체가 무의미함)
- 메시지 리스너 (RabbitMQ, Kafka 등 Spring Integration 기반)
- Spring Boot 통합 영역에서 제공하는 기본 executor 들이 가상 쓰레드를 사용하도록 재구성됨 (대부분의 TaskExecutor 기반 컴포넌트들)
마이그레이션 전략
- JDK 21
- 나온지 좀 됐기 때문에 공식 지원버전 이후(SpringBoot 3.2+) 껄로 사용해도 충분함.
- 단, pinning 쓰레드로 인한 성능저하가 있긴할텐데, 벤치마크 비교시 그래도 platform 쓰레드보단 동시처리능력이 더 뛰어남.
- JDK 25
- JDK 25엔 이것저것 바뀐것들이 많음. 특히 ScopedValue 관련 기능들이 많이 추가됨.
- → 아직 초기버전이기에 어떤 사이드 이펙트가 있을지 모르니 JDK의 신규 기능을 이용하기보단, 기존 JDK 기능을 사용하도록 유도
- → SpringBoot 3.5.5+ 로 사용
- 조금더 성숙해지면, 4로 업그레이드 및 소스코드 리팩토링
- JDK 25엔 이것저것 바뀐것들이 많음. 특히 ScopedValue 관련 기능들이 많이 추가됨.
✔ JDBC 드라이버 지원 버전
- PostgreSQL
- 42.6.0+
- 대부분 ReentrantLock 기반으로 변경, VT 친화적
- 대부분의 synchronized 메서드들이 ReentrantLock 등으로 대체되어 Pinning 문제가 해소되었다고 명시되어있음.
- Quarkus 공식 가이드 및 실제 이슈 토론 기준
- 이전
- 내부 synchronized로 인해 pinning 심함
- 42.6.0+
- MySQL Connector/J
- 9.0.0+
- ReentrantLock 사용으로 개선
- VT와 병행성 향상
- 공식 문서상에서 가상 쓰레드 지원이란 내용은 없으나, 비공식 블로그/기사에선 언급됨.
- JFR 이벤트 (jdk.VirtualThreadPinned)를 통해 검증 필요
- 8.x
- synchronized 사용으로 pinning 이슈 존재
- 9.0.0+
JDBC와 JDK 버전
- JDK 25(LTS)가 나온지 얼마 안되었고, JDK 24에서 적용된 pinning 해소 업데이트는 중요하나 24는 LTS가 아니라 고려 대상이 아닐거임.
- JDBC 벤더별로 차이는 있겠지만, synchronized → ReentrantLock으로 대체되어 pinning 이슈 해결된 드라이버라면 pinning 이슈 발생하는 상황 자체를 벗어난것이기 때문에 괜찮음.
- 따라서 JDBC 자체는 가상 쓰레드 친화적으로 업그레이드된 버전을 적용하되, JDK는 조금 보수적으로 21, 22를 적용해도 괜찮음.
- official로 pinning 해결에 대한 내용이 없는 드라이버라면 jdk pinning 감지
✔ 주의사항
1. ThreadLocal
가상 쓰레드도 ThreadLocal을 지원한다.
- ThreadLocal이란?
- JVM/Project Loom 스펙에서 가상 쓰레드는 플랫폼 쓰레드와 마찬가지로 thread-local 변수를 지원함.
- ThreadLocal, MDC, Spring의 TransactionSynchronizationManager 같은 것들은 “동일한 쓰레드 안에서”는 기존과 동일하게 동작함.
@Transactional 과 ThreadLocal
- Spring의 선언적 트랜잭션은 내부적으로 TransactionSynchronizationManager의 ThreadLocal을 이용해 현재 쓰레드에 트랜잭션 컨텍스트를 붙인다.
- 가상 쓰레드는 그냥 java.lang.Thread의 또 다른 구현체라 ThreadLocal 기반 구조가 동일하게 적용됨.
- 중간에 작업을 비동기 처리할 경우는 뭐 말 안해도 알테고.
Log4j
- 얘도 마찬가지로 ThreadLocal 기반이기 때문에 MDC 컨텍스트 전파는 문제 없음
ThreadLocal 사용에 객체 할당 시
- 수만~수백만 개 가상 쓰레드에 큰 객체를 ThreadLocal로 들고 있으면 메모리 / GC 부담이 커짐.
2. JDBC
JDK 21의 Socket 재구현과 JDBC의 관계
- JDK 21에서 네트워크 I/O (Socket, DatagramSocket, HttpURLConnection 기반) API는 블로킹 호출 시 가상 쓰레드가 언마운트(unmount) 될 수 있게 JVM 레벨에서 개선됨.
- 하지만 JDBC는 단순 소켓 호출이 아님
- DB 드라이버 내부 구현
- JDBC 스펙
- 전통적인 블로킹 API 설계
- 이런 부분들로 인해 호환성은 아래 방식으로 제공됨.
JDBC 최신 드라이버의 가상 쓰레드 호환 지원
- JDBC의 내부 I/O 블로킹이 쓰레드 pin 되지 않도록 개선
- MySQL : Connector/J 9.x
- PostgreSQL : JDBC 42.6.0+
- Oracle : JDBC 최신 드라이버
- 개선 포인트
- 기존 네이티브, 오래된 블로킹 방식 → 가상 쓰레드 aware 방식으로 교체됨.
- synchronized 범위를 줄이거나 제거 또는 대체 (ReentrantLock)
- 내부 락 사용 감소 또는 단기화
- JNI 호출 영역 최소화 및 언마운트 가능 시그널 유지
- read / write I/O 시 가상 쓰레드 unmount 허용
- 즉, 최적화 되었다고 보면 됨.
트랜잭션 구간에서 가상 쓰레드의 동작
@Transactional
public User getUser() { return jdbcTemplate.query(...); }
- SQL 실행 → 드라이버 내부에서 소켓 I/O 대기 → 가상 쓰레드는 unmount
- 실제 플랫폼 쓰레드는 다른 가상 쓰레드 수행
- 결과 도착 시 다시 mount → 로직 진행
- 즉, DB I/O 동안 CPU 리소스를 차지하지 않음. → 고동시성 처리에 유리함.
DB 트랜잭션 시 동시성 제어
- 호환 지원이란게 pool 사이즈에 맞춰서 뭔가 뾰로롱 하고 자동 설정이 되진 않음.
- 따라서 가상 쓰레드를 제어할 수단 필요 → 보통 세마포어
- DB Connection Pool Size는 여전히 제한됨.
- HikariCP max-pool-size 등
- 즉 가상 쓰레드는 블로킹이 싸졌을 뿐이지 DB 리소스는 싸지지 않았음.
- DB 서버 처리량(QPS)은 그대로임
- 트랜잭션은 락을 먹음
요약
| 항목 | 플랫폼 쓰레드 | 가상 쓰레드 |
| 소켓 I/O | 플랫폼 스레드를 점유함 | unmount → 플랫폼 스레드 해방 |
| 스레드 생성 비용 | 비쌈 | 매우 쌈 |
| 트랜잭션 락/대기 | 동일 | 동일 |
| DB connection pool | 동일 | 동일 |
| DB 서버 부담 | 동일 | 동일 |
| 세마포어 필요성 | 있음 | 중요 |
3. Pinned Virtual Threads 문제
- Virtual Thread Pinning이란?
- 가상쓰레드가 unmount되어야 하는 상황(I/O Blocking)에서 언마운트되지 않아 해당 가상쓰레드가 캐리어 쓰레드를 계속 점유하고 있는 상황
- → 다른 가상쓰레드를 캐리어 쓰레드가 할당받지 못해 성능 저하
- 가상쓰레드가 unmount되어야 하는 상황(I/O Blocking)에서 언마운트되지 않아 해당 가상쓰레드가 캐리어 쓰레드를 계속 점유하고 있는 상황
- 유발 원인
- synchronized 블록 또는 synchronized 메서드 내부에서 blocking I/O 수행
- synchronized void method() { ... I/O Blocking method() ... // I/O Stream }
- Native 메서드 호출 (JNI, JNA, foreign-function) 내부 블로킹
- synchronized pinning 은 JVM 레벨에서 발생 → Java object monitor에 의해 발생함.
- synchronized monitor는 OS mutex가 아니라 JVM monitor로 구현됨.
- → JVM 모니터는 carrier thread에 귀속됨.
- → 따라서 VT 언마운트 불가 → carrier thread가 붙잡힘(pinned)
- 해당 문제는 JDK 21, 22, 23에 있었고 JDK 24+ 에서 개선됨.
- 특히 JDK 24에서 문제 해결되고, 25에서 추가 개선
synchronized pinning을 피하는 코드 전략
- synchronized 블럭 대신 Lock 사용
- ReentrantLock 이나 StampedLock 사용
- synchronized는 carrier thread 레벨에서 lock을 잡음
- ReentrantLock은 VT 단위에서 lock을 관리함.
- 필요 시 virtual thread unmount 가능
- → ReentrantLock은 pinning 방지
- ReentrantLock 이나 StampedLock 사용
- synchronized 영역 최소화
- Thread-safe해야 하는 부분만 잠그고, 블로킹 I/O는 sync 블럭 밖으로 분리
- 상태 공유를 줄이고 immutable 객체로 설계
- barrier 없이 분산 처리 가능
- ThreadLocal을 ScopedValue로 전환
- ScopedValue는 final로 지정됨.
- ScopedValue
- thread inheritance 없음
- clone 안됨
- 따라서 per-request 모델인 tomcat과 VT와 궁합이 좋음
Pinning 감지 방법
- Java 실행 옵션 (JDK 21 ~ 23)
- -Djdk.tracePinnedThreads=full
- JFR 이벤트 체크
- jdk.VirtualThreadPinned 켜고 stack trace 확인
4. 가상 쓰레드 생성 제한
- 가상 쓰레드는 기존 플랫폼 쓰레드에 비해 가벼운 쓰레드라 많은 수의 쓰레드를 생성하는 것이 가능하지만, 컴퓨팅 리소스는 유한하기 때문에 무제한 생성하기는 힘들다.
- 생성을 제한하는 공식 API는 없으나 폭증을 우려하여 제한하고 싶은 경우 직접 별도 제어 계층을 둬야 한다.
제어 방법
1) Semaphore / 토큰 버킷 / RateLimiter
- VT 생성 속도 또는 동시 실행 중인 VT의 상한값을 제어하는 가장 단순한 방법
- VT 자체는 무한히 생성 가능하지만 실행 흐름을 제어하는 로직으로 제한하는 모델.
2) Bounded Executor (임계치가 있는 실행기)
- VT를 직접 생성하지 않고, ExecutorService 래퍼로 동시 실행 가능한 VT 수를 제한하는 방식
- ExecutorService vtExec = Executors.newVirtualThreadPerTaskExecutor(); ExecutorService bounded = new BoundedExecutor(vtExec, maxVirtualThreads);
- JDK 내부 방식을 활용
- FJP 기반으로 직접 제한 Executor 구성
- parallelism 조절
- 제출량(queue length) 제한
- “Task 제출 → VT 생성 → 실행” 흐름을 간접적으로 제한 가능
- FJP 기반으로 직접 제한 Executor 구성
3) Queue + Backpressure 모델
Producer 가 VirtualThread를 만들어 task 수행시키는 방식이라면, 중간에 크기가 제한된 BlockingQueue 를 두어 처리하는 방식 (Producer-Consumer 패턴)
- Queue 가 꽉 차면 producer wait/reject
- Queue 가 비워지면 다시 VT 제출 가능
이런 방식으로 전반적인 VT 생성 속도를 제어할 수 있음.
- 장점
- VT 생성 전에 “버퍼 압력(backpressure)”을 발생시켜 과도한 생성 방지.
4) ThreadFactory wrapper로 카운팅 제한
VirtualThreadFactory 를 감싸서:
- 매 생성마다 atomic counter 증가
- counter > limit 이면 생성 거부 / 대기
ThreadFactory f = Thread.ofVirtual().factory();
ThreadFactory limited = r -> {
if (COUNT.get() >= LIMIT) throw new RejectedExecutionException();
COUNT.incrementAndGet();
return f.newThread(r);
};
- 장점
- VT “생성 자체”를 제어
- 단점
- “blocked → parked → unparked” 상태 전이를 포함한 실행 중 전체 수를 제어하진 못한다.
5. Blocking I/O 시 주의사항
- 대용량 파일 + memory-mapped + 파일 락/권한 조작 + 메타데이터 조작과 같이 native/OS 수준 호출이 개입될 여지가 있는 경우
- 외부 라이브러리(JDBC, ZIP, compression, OS-specific 파일 조작 등)가 native 호출을 포함하는 경우.
- → 이 경우 VT 친화성 여부를 별도 확인해야함.
- 판단 기준
- JDK 기본 스트림 / 채널 파일 I/O → VT 써도 괜찮음
- native / native wrapper 라이브러리 → 검토 필요
JDK I/O Operator 관련 호환성
VT unmount 자동화 기준
Blocking 연산 분류
- 완전 지원 (언마운트 가능)
- blocking 시 가상 쓰레드만 멈추고 캐리어는 다른 가상 쓰레드를 처리할 수 있도록 언마운트됨.
- 부분 지원(보정 / compensation)
- 어떤 이유로 언마운트는 안되지만, JDK 스케줄러가 캐리어 풀 parallelism을 일시적으로 늘려 OS 쓰레드 캡처를 보정함.
- 가상 쓰레드는 pinning이라 하지 않고 capture된 OS 쓰레드를 보정(compensate)하는 형태
- 미지원(실제 pinning)
- 블로킹 중 가상 쓰레드가 캐리어에서 언마운트될 수 없음.
- 해당 캐리어(OS 쓰레드)가 그동안 완전히 묶이기 때문에 스케일에 직접적인 영향
JDK 21 ~ 23
완전 지원 (VT aware)
- 네트워크 I/O
- java.net
- java.nio.channels
- java.util.concurrent
- LockSupport
- ReentrantLock
- Semaphore
- BlockingQueue.take()
- etc
- sleep() / join() / park()
- Thread.sleep(), Thread.join(), LockSupport.park() …
- java.io.InputStream / OutputStream 및 하위 스트림들
- BufferedInputStream, BufferedOutputStream, FileInputStream, FileOutputStream 등 기존 동기 블로킹 I/O 스트림 사용 가능
- java.io.Reader / Writer 계열
- 문자 기반 스트림 I/O (FileReader, FileWriter, BufferedReader, BufferedWriter, … )
- NIO, NIO.2 기반 파일 채널, 파일 시스템 접근, 파일 열기, 읽기/쓰기, 채널 기반 I/O 등
- java.nio.channels.*
- java.nio.file.Path + java.nio.file.Files API
- java.nio.channels.SeekableByteChannel, AsynchronousFileChannel 등
부분 지원 (보정(compensation) 처리)
- Object.wait() / timed wait
- 언마운트 불가 + 보정(compensation).
- 일부 파일 I/O (파일 시스템 호출 :: Bug : JDK-8329593)
- NIO Selector.select()
- java.io.FileDescriptor.sync()
- → FileChannel.force(), RandomAccessFile.getFD().sync() 등에서 사용
- java.nio.MappedByteBuffer.force() / java.lang.foreign.MemorySegment.force()
- 파일이 direct I/O로 열려 있을 때 read/write
- StandardOpenOption.SYNC/DSYNC 같은 synchronized I/O file integrity 옵션으로 연 파일에 대한 write
- OS 레벨 제약으로 비동기화 불가인 FS연산은 VT 언마운트가 안되나, JDK 스케줄러가 보정 방식으로 처리함
- 네트워크
- InetAddress.lookupBy* (DNS 조회)
- System.in/out, err read/write
미지원
- synchronized
- JNI / native / FFM
- 클래스 로딩 / 초기화
JDK 24+
JEP 491 적용, JDK-8329593 버그 픽스(JDK23) 후 변화
- 일반 buffered 파일 I/O에 대한 보정 제거
- 일반 FileInputStream/FileOutputStream/RandomAccessFile로 연 파일
- Files.* 계열이 기본 옵션으로 여는 보통의 파일
- Object.wait() / timed wait (부분지원) → 완전 지원
- (synchronized + 파일 I/O) → 완전 지원
- 요약
- 일반 buffered 파일 I/O: 그냥 OS 블로킹 취급, 추가 보정 없음
- fsync/force/direct/SYNC/DSYNC, System/Process I/O: 여전히 보정 대상
- synchronized에 의한 pinning 제거(JEP 491)로, 파일 I/O를 락 안에서 해도 VT 스케줄링 관점에서는 훨씬 안전
주의 사항
- 지원하지만 보장 불가 / 환경에 따라 달라질 수 있는 경우
- OS나 FS가 비동기 I/O, non-blocking I/O를 제대로 지원하지 않는 경우
- 특정 파일 시스템 호출
- 메타데이터 조회, 파일 속성 변경, 디렉토리 탐색, 권한 변경, 파일 락 등의 내부 구현이 native 메서드 또는 blocking system call 기반이라 VT 언마운트가 안되어 pinning 또는 보정(compensation) 대상이 될 수 있음.
- 대용량 파일 복사 / memory-mapped 파일 I/O (ex. FileChannel.map())
- JNI/native 또는 OS 종속 호출이 개입될 여지가 있어 VT 친화 여부가 구현에 따라 다름.
- 일부 legacy 라이브러리
- 내부적으로 native I/O (JNI)를 사용하거나 blocking native호출을 추상화한 라이브러리
- 즉 일반적인 파일 read/write, I/O는 대체로 안전함.
요약
- VT-관련 파일 I/O 경계에 직접적으로 관여하는 핵심 클래스/패키지(23+ 기준):
- java.io
- FileDescriptor (sync)
- FileInputStream, FileOutputStream, RandomAccessFile
- java.nio / sun.nio.ch
- FileChannelImpl (read/write, force, direct I/O)
- MappedMemoryUtils + MappedByteBuffer
- java.nio.file
- Files.* (내부적으로 위 스트림/채널 사용)
- StandardOpenOption.SYNC, DSYNC (synchronized file integrity)
- 플랫폼별 FS/NIO 구현 (UnixFileSystem, WinNTFileSystem, UnixNativeDispatcher, WindowsNativeDispatcher 등)
- java.io
- VT 보정/블로킹 정책이 명시적으로 구분된 파일 I/O 종류:
- 일반 buffered I/O (위 스트림/채널의 기본 모드)
- → 21/22: 보정 대상 → 23+부터 보정 제거
- 고비용 I/O (sync/force, direct, SYNC/DSYNC, System/Process I/O)
- → 21~25 전반에 걸쳐 계속 보정 대상
- VT pinning과 직접 연결된 건 JDK 21의 synchronized/Object.wait()였고, JEP 491 이후(24+)는 파일 I/O 관점에서 pinning은 ‘native/FFM 안에서 블로킹될 때’ 정도만 남는다.
✔ 가상 쓰레드의 한계점
Silver bullet은 없는것 처럼 가상 쓰레드도 만능이 아님
가상 쓰레드의 설계 목적
가상 쓰레드는 '경량 쓰레드 + JVM-스케줄링 + 블로킹 I/O 자동 unmount → OS 쓰레드 자원 절감'을 목표로 한다.
- 모든 블로킹 + 동시성 시나리오에 무조건 최적이 아니라, 몇 가지 설계상 / 구현상 제약이 있음.
주요 단점과 한계점
- 위의 단점 쪽에서 언급했던것 처럼 CPU-bound 작업에선 VT 이점이 거의 없음.
- VT는 I/O-bound, Blocking 위주의 작업에 최적화된 설계.
- CPU-bound 연산에선 기존 플랫폼 쓰레드나 병렬 처리 모델 대비 특별한 이득이 없음.
- 즉, VT는 동시성(concurrency + 많은 작업들의 I/O 대기)을 처리하는덴 유리하나, 병렬성(parallel CPU-bound)에는 제한이 있음.
리소스 한계는 피할 수 없음
- 병목은 외부 자원에 남음
- VT가 아무리 많아도, 실제 처리 병목은 I/O, DB 커넥션, 네트워크, 메모리, GC, 커넥션 풀 등 외부 자원/환경에 의해 결정됨.
- VT는 단지 쓰레드 운영 비용을 낮출뿐임.
Throughput 관리 어려움, 리소스 과다 사용 가능성
- VT는 가볍고 많이 생성할 수 있다는 장점 덕분에 동시 요청 수 폭증에 쉽게 대응할 수 있지만, 이로 인한 외부 자원들에 대한 사용량이 폭증할 수도 있어, 시스템 전체 리소스 한계에 빨리 도달할 수 있음.